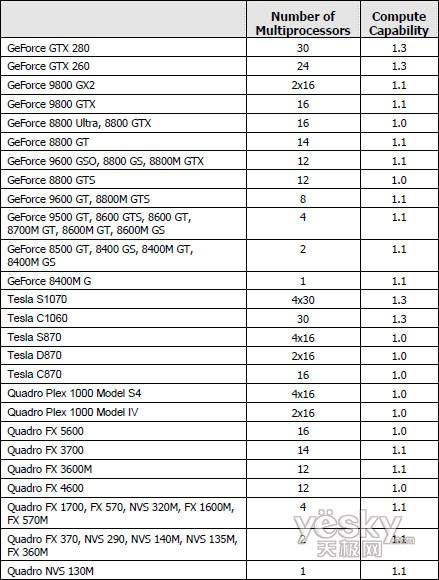
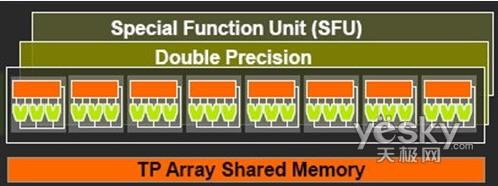
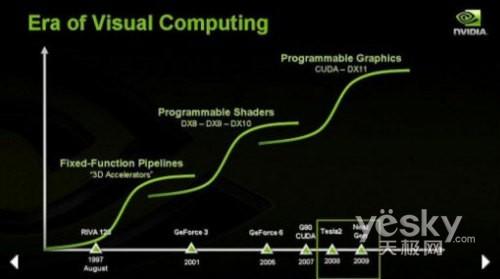
已有 4705 人浏览分享
举报 使用道具
本版积分规则 发表回复 回帖并转播 回帖后跳转到最后一页
0
21
20
Thinkpad E14 内存屏蔽罩安装上后
有没有人知道ThinkBook 14+ BIOS升
Thinkpad X1 carbon gen10 摄像头
Thinkbook 16P 2024款,扬声器异常
关于 t14p
Thinkbook 14 G3 ITL 体验报告
优质服务商家
严格准入,海量云服务
7*8小时在线服务
实时咨询,安心购物
专业测试 品质保证
安全监测,保证品质
退款售后无忧
不满意可退款
微信公众平台
扫描访问手机版
Archiver|手机版|小黑屋|水窝ibm
GMT+8, 2025-2-25 18:29 , Processed in 0.095120 second(s), 23 queries .
Powered by Discuz! X3.5
© 2001-2022 Comsenz Inc.
客服电话
电子邮件
在线时间:8:00-16:00



 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 显身卡
显身卡